- Hi, it's glad to see you again./
- Posts/
- OSTEP Chapter8: Scheduling - The Multi-Level Feedback Queue Review/
OSTEP Chapter8: Scheduling - The Multi-Level Feedback Queue Review
Table of Contents
Question: How to schedule without perfect knowledge?
The last chapter mentioned that we had an assumption that does not match reality: we know the execution times of all Jobs.
Obviously, we do not know the execution times of Jobs, hence we developed a mechanism called Multi-level Feedback Queue (MLFQ).
Multi-level Feedback Queue (MLFQ) #
Objectives #
- Improve Turnaround time
- Improve Response time
Basic Settings #
- There are many different Queues
- Different Queues can have different time-slice lengths
- For example, we have two Queues:
- Jobs in Queue A run for 10ms each time
- Jobs in Queue B run for 100ms each time
- For example, we have two Queues:
- Each Queue has different priorities
Basic Rules #
- Jobs with the highest priority are executed first
- Under the same priority, Jobs are executed using Round-Robin
- Newly arrived Jobs have the highest priority
- If a running Job uses up its allotted time and is not yet complete, its priority is reduced.
- If a running Job relinquishes CPU control before using up its time, its priority remains unchanged.
Examples #
Let’s take a look at the scenarios encountered under these rules
Long-running Job #
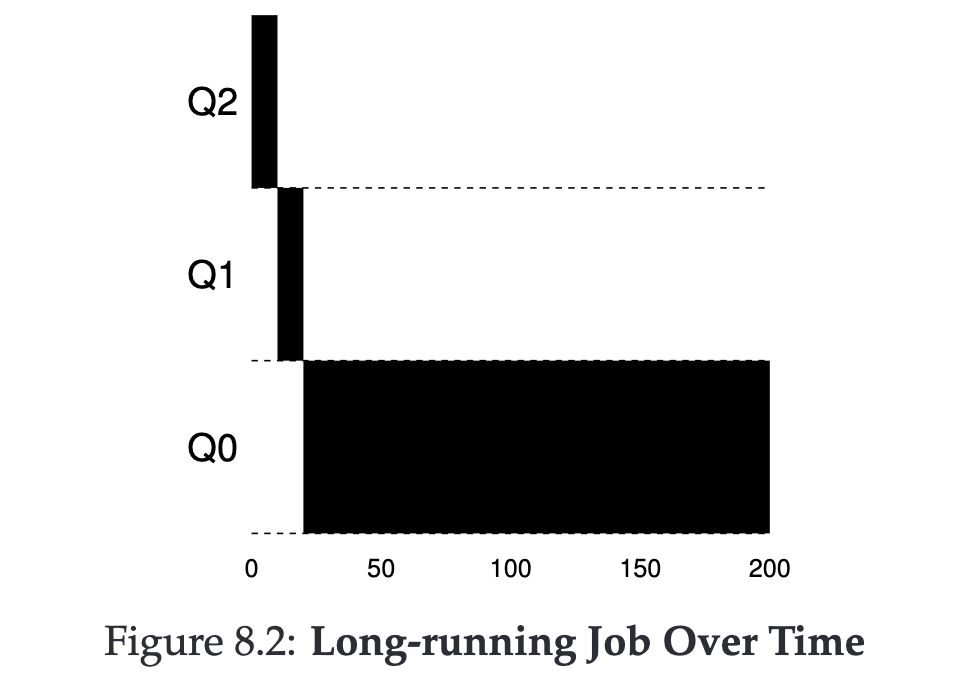
- Job enters the system, initially at the highest priority
- Executes, uses up Q2 time-slice, priority drops (Q2 -> Q1)
- Executes, uses up Q1 time-slice, priority drops (Q1 -> Q0)
- Completes the entire program
Multiple Jobs #
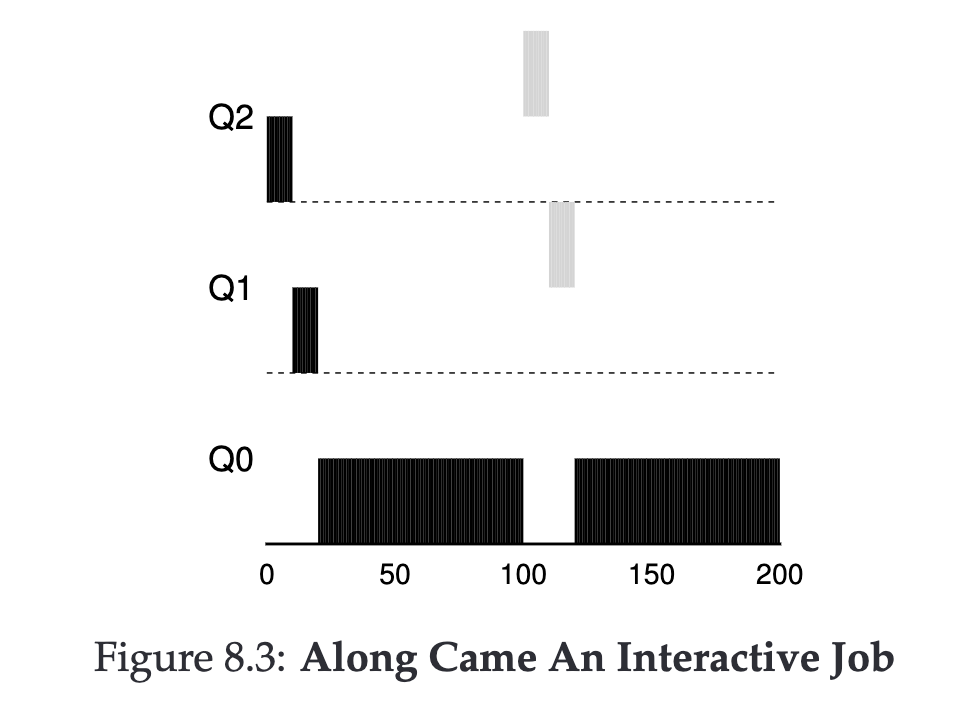
- JobA enters the system with high priority
- JobA uses up the entire time slice, priority drops (Q2 → Q1)
- JobA uses up the entire time slice, priority drops (Q1 → Q0)
- Runs JobA, then stops
- JobB enters the system with high priority
- JobB uses up the entire time slice, priority drops (Q2 → Q1)
- JobB runs and completes
- JobA runs and completes
I/O Intensive Job and CPU Intensive Job #

- JobA enters the system with high priority
- JobA uses up the entire time slice, priority drops (Q2 → Q1)
- JobA uses up the entire time slice, priority drops (Q1 → Q0)
- Runs JobA, then stops
- JobB enters the system with high priority
- JobB relinquishes CPU (due to I/O operations), priority remains unchanged (Q2)
- JobA runs → JobA stops → JobB runs → JobB stops… This cycle continues until both JobA and JobB are completed
Issues #
After seeing many examples above, we identified two potential issues:
- Starvation: If we have many high-priority Jobs, then lower priority Jobs will not get a chance to execute.
- Malicious Users: If a process intentionally pauses just before the end of its time-slice, it can maintain high priority and control the CPU for an extended period.
How to solve Starvation? #
Let’s first try to address Starvation, because it is caused by high-priority Jobs potentially occupying the CPU for a long time, preventing lower priority Jobs from executing. We can consider raising all Jobs to the highest level every specific time interval (maybe 1 second?).
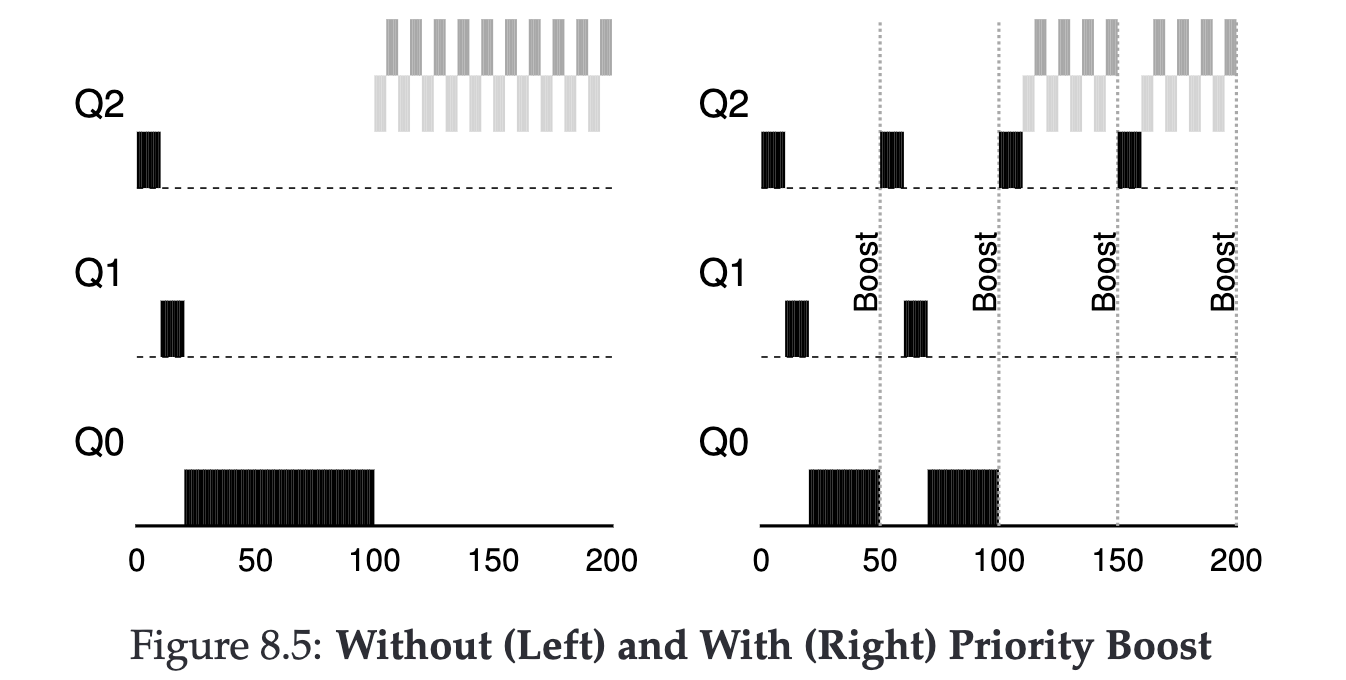
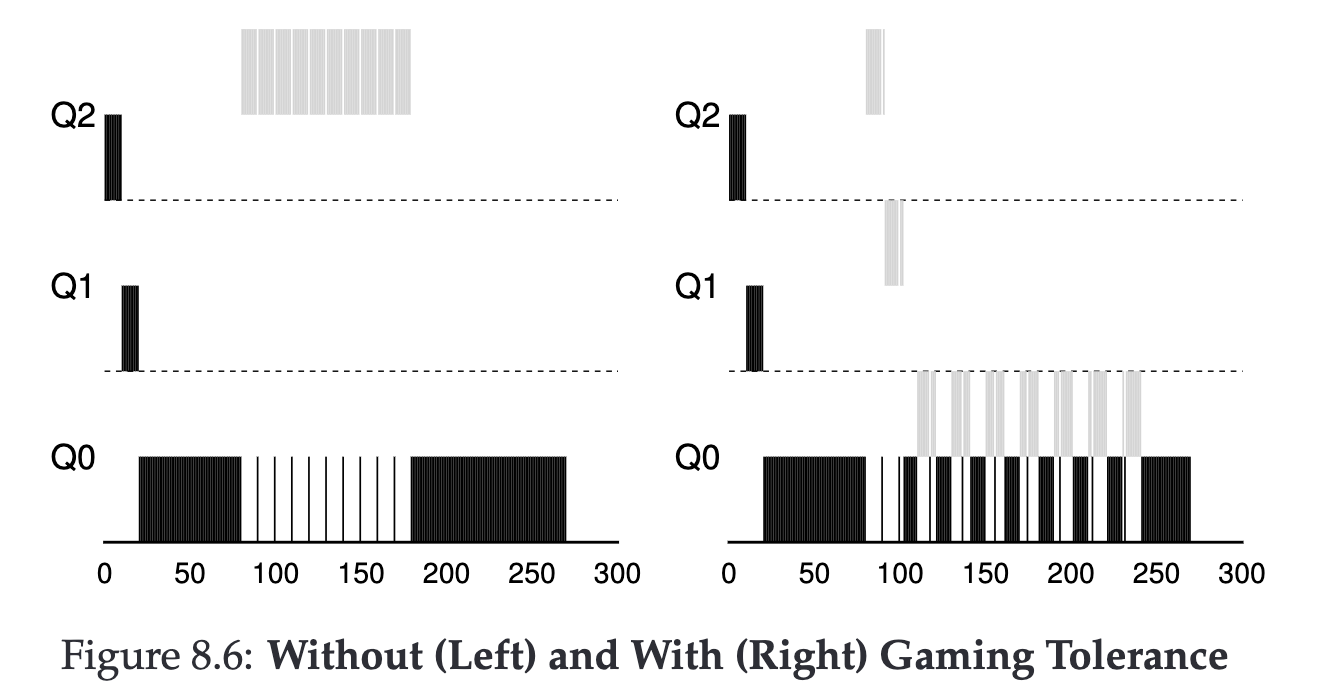
How to deal with Malicious Users? #
There are some loopholes in our rules 4-1 and 4-2 combination that could be exploited.
We can consider redefining a new rule:
A Job, after using up the time-slice of that Queue (no matter how many times it relinquished CPU control), should have its priority lowered.
Key Settings #
After seeing the above examples, we can see several key settings that affect the performance of the Scheduler:
- How many Queues are needed?
- How large should the time slice for each Queue be?
- How often should all Jobs be elevated to the highest privilege?
There is no perfect setting, so operating systems usually provide a default value, allowing users to modify it according to their needs.
Are there other ways? #
All the designs mentioned above are based on improving turnaround time and response time. In the next chapter, we will discuss other design methods.