OSTEP Chapter9: Scheduling - Proportional Share Review
Table of Contents
Question: How to share the CPU proportionally?
In the previous chapter, we mentioned using turnaround time and response time as metrics to design Schedulers.
This chapter lets us consider from different perspectives, we try to proportionally distribute CPU resources to each process.
Lottery Scheduling #
Basic Logic #
The fundamental idea of Lottery Scheduling is that the more tickets a process has, the higher its chance of being executed.
Example #
- Process A has 75 tickets
- Process B has 25 tickets
And we randomly pick a number between 1-100 to decide which process to execute.

Other Mechanisms #
Lottery Scheduling also has some other mechanisms allowing users to transfer tickets among processes, letting us adjust according to the situation.
Ticket Currency #
This mechanism allows the allocated tickets to be distributed among the Process Group based on their own ratio; then, the operating system automatically calculates the proportion each process should occupy.
For example,
- User A and User B each have 100 tickets.
- User A has two jobs, allocated (500/1000)
- User B has one job, given (10/10)

Honestly, I’m a bit unclear about the purpose of this mechanism? Why not just use the original tickets for distribution?
Ticket Transfer #
This mechanism allows you to temporarily transfer tickets between processes, enabling a temporary increase in priority for some processes.
Ticket Inflation #
This mechanism is only suitable when processes mutually trust each other because temporarily inflating tickets can achieve a higher priority. However, if a malicious process does this, it will prevent other processes from accessing CPU resources.
Implementation #
Implementing a Lottery Scheduler might look like this:
// counter: used to track if we’ve found the winner yet
int counter = 0;
// winner: use some call to a random number generator to
// get a value, between 0 and the total # of tickets
int winner = getrandom(0, totaltickets);
// current: use this to walk through the list of jobs
node_t *current = head;
// loop until the sum of ticket values is > the winner
while (current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
// ’current’ is the winner: schedule it...
To make the Lottery Scheduler most efficient, create a sorted Process List.
This way, the operating system’s efficiency in selecting processes is maximized.
Issues #
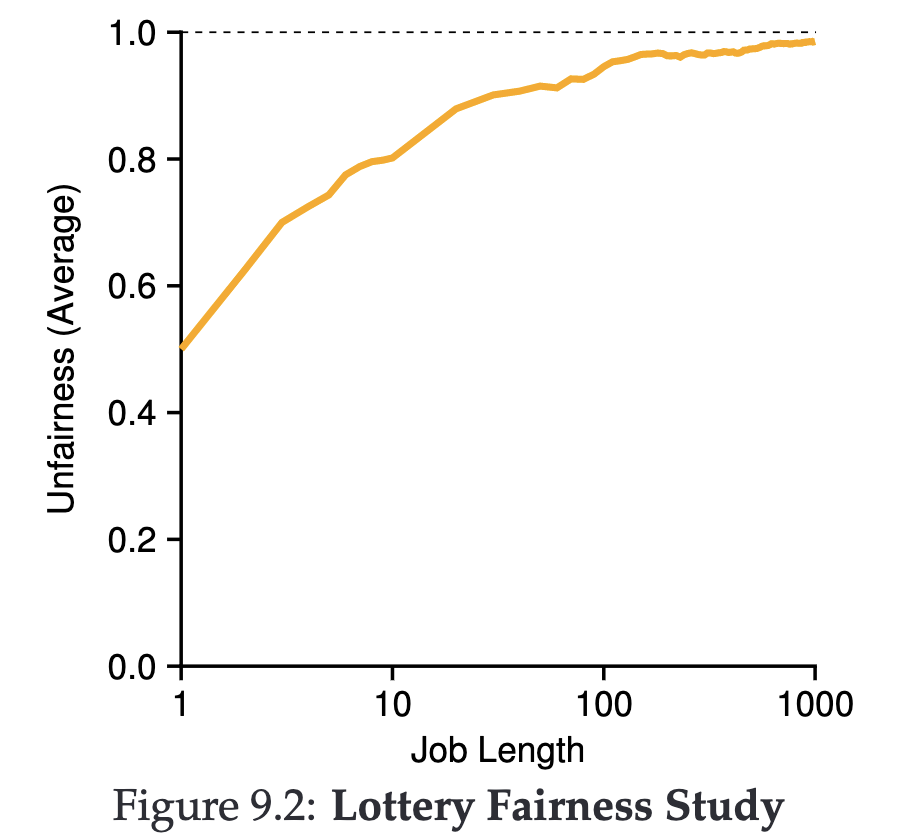
A common issue with Lottery Scheduling is that shorter job execution times might lead to more unfairness.
Stride Scheduling #
To address potential unfairness, we developed another Scheduling.
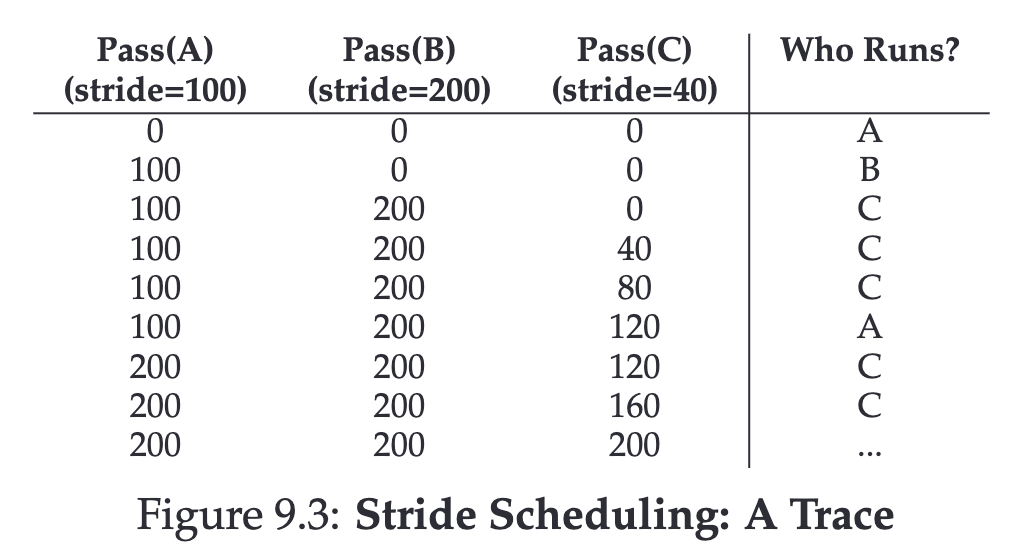
The concept of Stride Scheduling is that each job has a stride, which is inversely proportional to the number of tickets it holds.
For example,
- Process A has 100 tickets
- Process B has 50 tickets
- Process C has 250 tickets
We can calculate each one’s stride by dividing a large number by the number of tickets allocated to each process. For instance, if we divide 10,000 by these ticket values, we get:
- Process A: 100
- Process B: 200
- Process C: 40
Each time we execute that Process, we add their stride. And each time, we select the one with the lowest stride to execute.
Example #
Completely Fair Scheduler (CFS) #
Besides proportionally distributing CPU resources, we also have another idea for designing a Scheduler, which is to fairly distribute CPU resources to all processes.
Objective #
To evenly distribute CPU resources to all processes.
Method #
Every time a process is executed, its execution time length (vruntime) is calculated.
Each opportunity to switch processes, we choose the process with the smallest vruntime.
In CFS, there are two key parameters:
sched_latency: the time length each process runs (usually 48 ms)min_granularity: the shortest time a process runs (usually 6 ms)
For example, in a system with 4 processes, the execution time will be 48 / 4 = 12 ms, switching to another process every 12 ms.
In another example, in a system with 10 processes, the execution time will be 48 / 10 = 4.8 ms, but due to min_granularity, switching to another process every 6 ms.
Example #
- There are 4 processes running
- CFS divides
sched_latencyby 4, giving each process a time slice of 12 ms. - CFS then runs the first process until it uses up its 12 ms (vruntime) and checks for any process with a lower virtual runtime available to run.
- CFS will switch to one of the other three processes, and so on.
- All four processes (A, B, C, D) each run two time slices in this manner; two of them (C, D) subsequently finish, leaving only two, then each runs for 24 ms in a loop.
Weight #
CFS also provides priority features (nice), with different weights set according to different nice settings. Weight.
Then, based on the Weight, calculate the runnable time.

Improving Scheduler Efficiency #
There are many factors that affect Scheduler efficiency, one of which is how quickly the Scheduler can locate the process it has decided to run.
In CFS, processes use Red-Black Trees to manage.