OSTEP 第八章 Scheduling: The Multi-Level Feedback Queue
·235 字·2 分鐘
目錄
核心問題:要如何在不知道 Job 執行時間設計出好的 Scheduler ?
上一個章節最後提到,我們還有一個假設不符合現實情況:我們知道所有 Job 的執行時間。
顯然我們沒有辦法知道 Job 的執行時間,所以我們發展的一套機制 Multi-level Feedback Queue (MLFQ)。
Multi-level Feedback Queue (MLFQ) #
目標 #
- 提升 Turnaround time
- 提升 Response time
基本設定 #
- 有許多不同的 Queue
- 不同的 Queue 可以有不同的 time-slice 長度
- 舉例來說我們有兩個 Queue
- Queue A 內的 Job 每次執行 10ms
- Queue B 內的 Job 每次執行 100ms
- 舉例來說我們有兩個 Queue
- 每個 Queue 會有不同的優先級
基本規則 #
- 優先極高的 Job 先執行
- 相同優先級情況下,用 Round-Robin 去執行 Jobs
- 新進的 Job 的優先級都是最高的
- 如果執行的 Job 用完他的執行時間且還沒有執行完成。降低它的優先級。
- 如果執行的 Job 在用完他的執行時間前放棄 CPU 的控制,優先級不變。
範例 #
讓我們一起來看看根據這些規則下遇到的情況
長時間 Job #
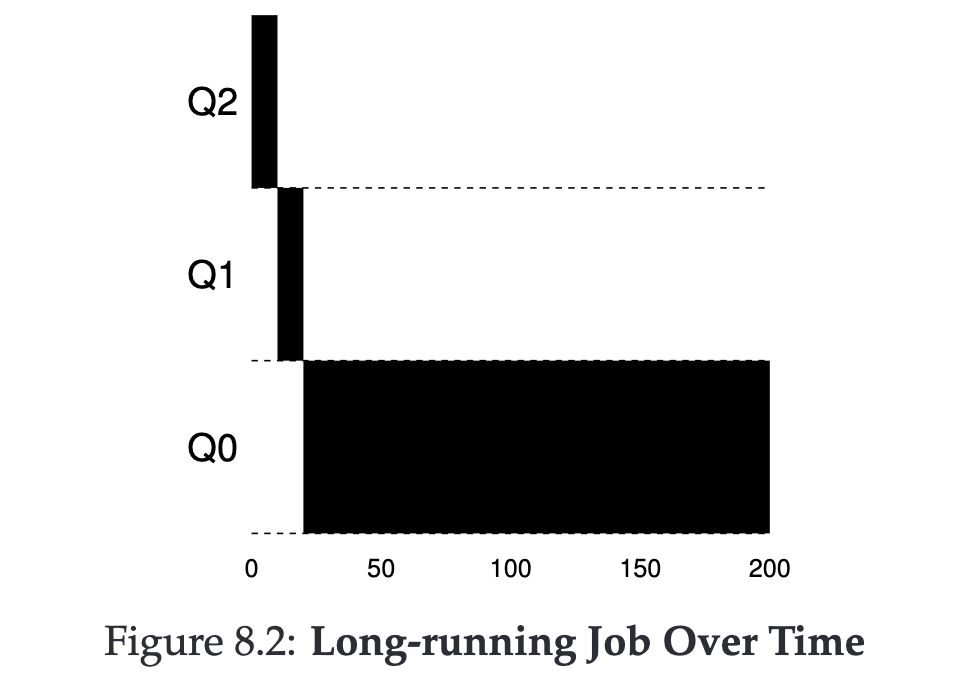
- Job 進入系統,預設為最高優先級
- 執行,用完 Q2 time-slice 下降優先級(Q2 -> Q1)
- 執行,用完 Q1 time-slice 下降優先級(Q1 -> Q0)
- 執行完整個程式
多個 Job #
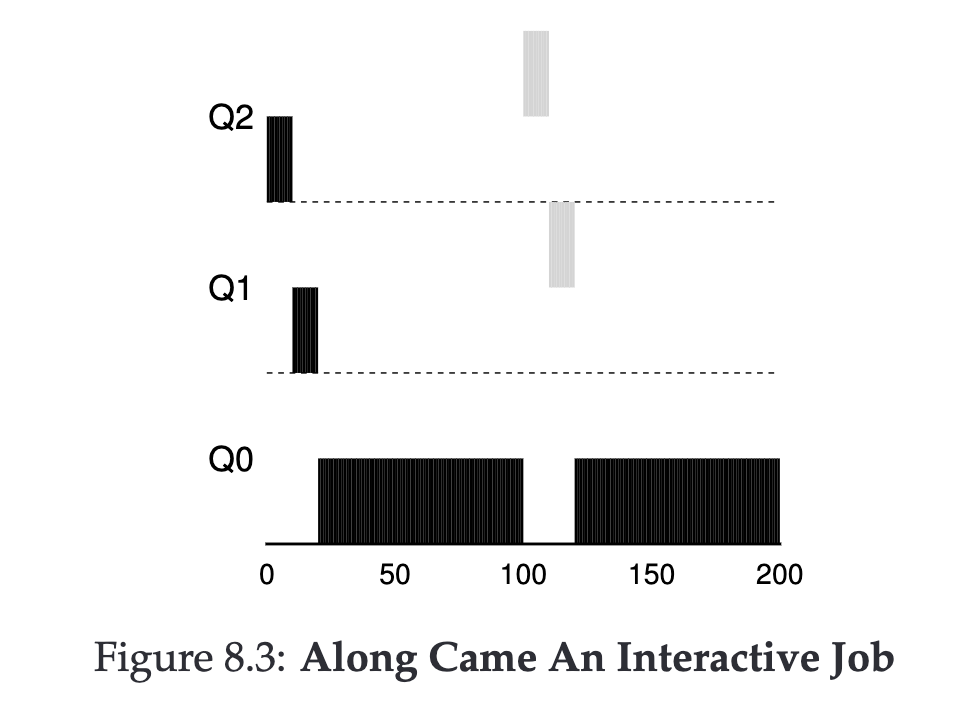
- JobA 進入系統,擁有高優先權
- JobA 使用完整個時間片後降低優先權(Q2 → Q1)
- JobA 使用完整個時間片後降低優先權(Q1 → Q0)
- 運行 JobA,然後停止
- JobB 進入系統,擁有高優先權
- JobB 使用完整個時間片後降低優先權(Q2 → Q1)
- JobB 運行並完成
- JobA 運行並完成
IO 密集 Job 與 CPU 密集 Job #

- JobA 進入系統,擁有高優先權
- JobA 使用完整個時間片後降低優先權(Q2 → Q1)
- JobA 使用完整個時間片後降低優先權(Q1 → Q0)
- 運行 JobA,然後停止
- JobB 進入系統,擁有高優先權
- JobB 放棄 CPU (因為執行 I/O 相關的操作),優先級保持不變(Q2)
- JobA 運行 → JobA 停止 → JobB 運行 → JobB 停止…如此循環,直到 JobA 和 JobB 都完成
問題 #
看完上面許多的範例之後,我們發現有兩個潛在的問題
- Starvation:如果我們有很多優先權高的 Jobs 那麼優先級較低的 Job 就無法被執行到了。
- 惡意的使用者:如果有一個 Process 在 time-slice 結束前刻意暫停,這樣它就可以一直佔據著高優先級,並長時間控制著 CPU 。
如何解決 Starvation ? #
我們先來嘗試解決 Starvation ,因為 Starvation 的成因是因為高優先級的 Job 有可能佔據長 CPU 時間導致低優先級的 Job 無法執行。於是我們可以考慮每隔特定時間(也許 1s ?)我們把所有的 Job 都提高到最高級。
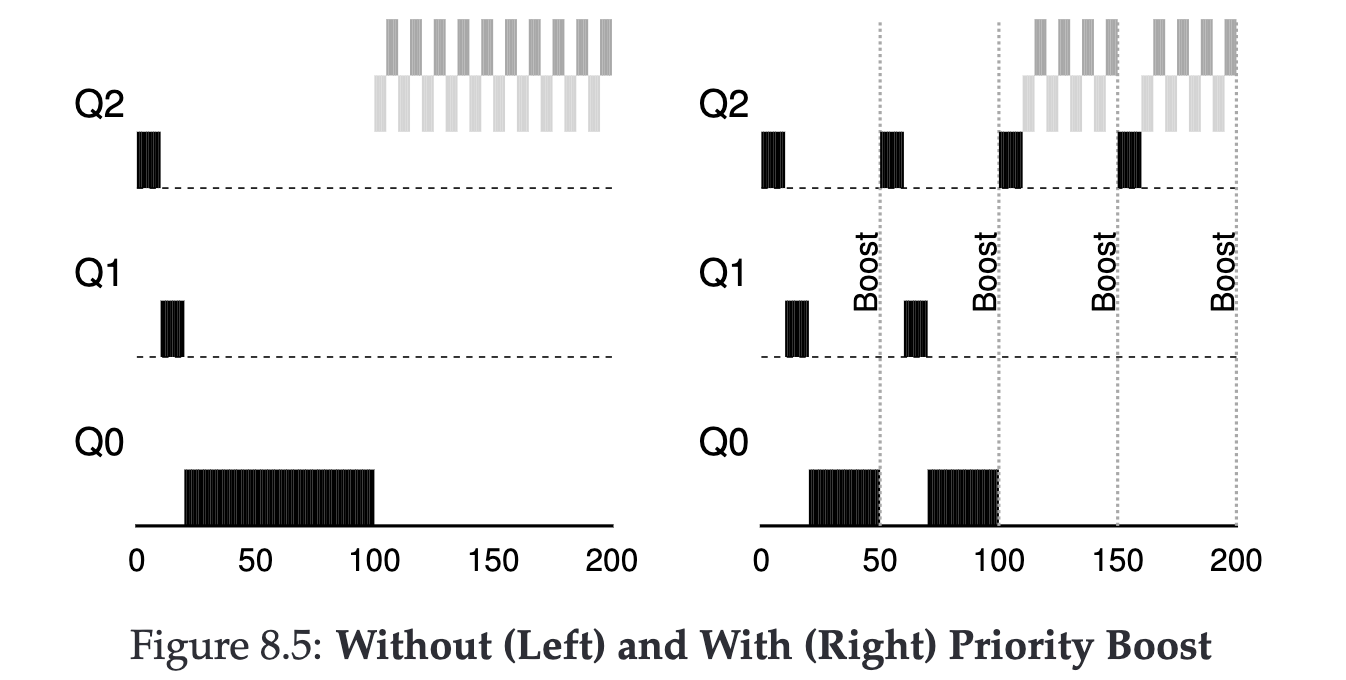
如何解決惡意的使用者? #
我們的規則 4-1, 4-2 的組合有一些漏洞,導致可能被別人惡意利用。
我們可以考慮重新定義一個新的規則:
一個 Job 只要用完該 Queue 的 time-slice (無論中間放棄了幾次 CPU 控制),就降低他的優先級。
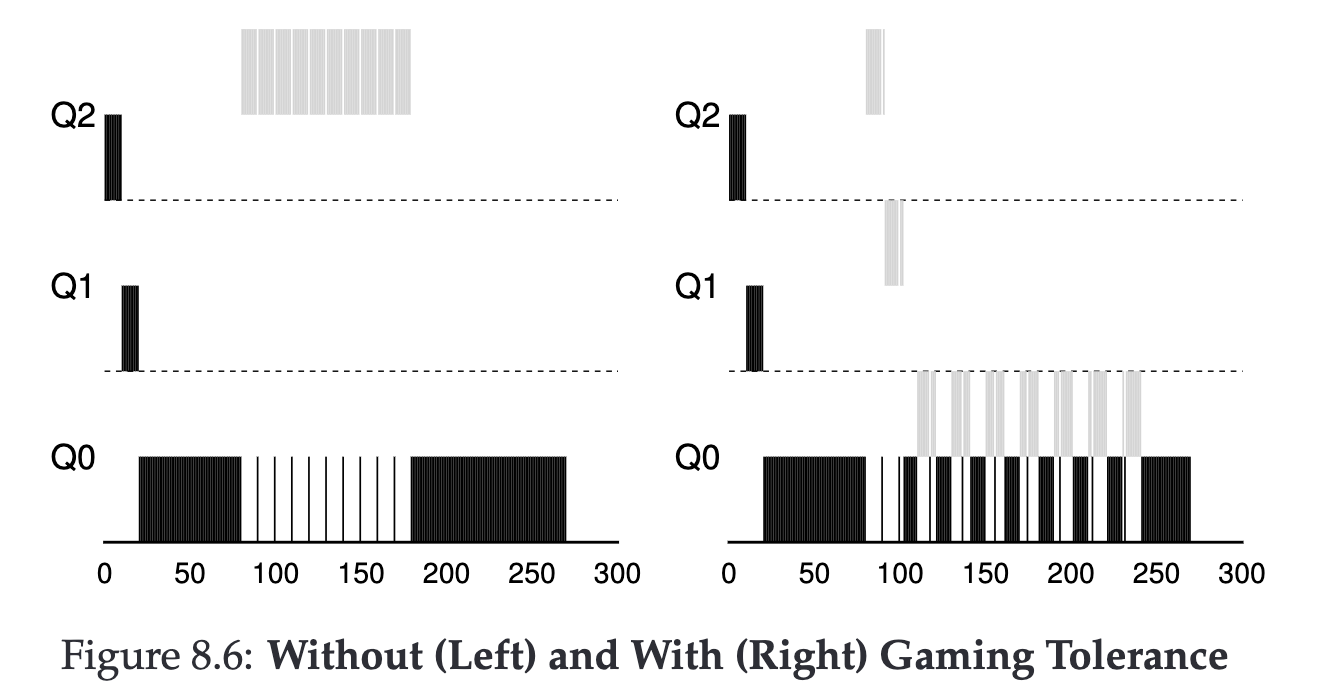
關鍵設定 #
看完以上範例,我們可以知道有幾個關鍵的設定會影響 Scheduler 效能
- 需要多少 Queue ?
- 每個 Queue 要設定多大的 time slice ?
- 多久的時間間隔把所有的 Jobs 推到最高權限?
沒有一個完美的設定,所以作業系統通常都會提供一個預設的值,讓使用者可以根據自己的需求去做修改。
還有什麼其他的方式嗎? #
以上的設計都是基於提升 turnaround time 與 response time 的角度去設計。下一章我們會討論其他的設計方法。