OSTEP 第九章 Scheduling: Porportional Share 重點整理
目錄
核心問題:如何等比例的分配 CPU 資源?
上一個章節我們提到,用 turnaround time 與 repsonse time 作為指標去設計 Scheduler
這個章節讓我們來看看已不同角度來思考,我們盡可能等比例的分配 CPU 的資源給各個 Process。
樂透 Scheduling (Lottery scheduling) #
基本邏輯 #
Lottery scheduling 的基本理念就是 Process 如果有越多的 ticket 就有越高的機會被執行到。
範例 #
- Process A 有 75 張 ticket
- Process B 有 25 張 ticket
並且我們隨機的在 1-100 間選取數字,來決定要執行哪個 Process

其他機制 #
樂透 Scheduling 也針對 ticket 有一些其他機制讓 User 可以在 Process 之間轉換,讓我們可以依情況做調整
Ticket Currency #
這個機制可以讓分到的票在 Process Group 裡面依自己比值去做分配;然後作業系統會自動依照比值算出每個 Process 的佔比應為多少。
舉個例子
- User A 跟 User B 各有 100 張 tickets
- User A 有兩個 Job ,分別給它們 (500/1000)
- Uesr B 有一個 Job ,給它 (10/10)

老實說我有點不太清楚這個機制的用意?為什麼不直接拿原始的 ticket 來分配就好?
Ticket 轉換 #
這個機制可以讓你在 Process 之間戰時轉換 ticket ,讓你可以暫時性的提高某些 Process 的優先權。
Ticket 通膨 #
這個機制只適合用在 Process 之間都互相信任,因為短暫的讓 Ticket 通膨可以獲得更高的優先級,但如果有惡意的 Process 這樣做,只會讓其他 Process 沒有機會得到 CPU 資源
實作 #
Lottery Scheduler 的實作可能會像是這樣
// counter: used to track if we’ve found the winner yet
int counter = 0;
// winner: use some call to a random number generator to
// get a value, between 0 and the total # of tickets
int winner = getrandom(0, totaltickets);
// current: use this to walk through the list of jobs
node_t *current = head;
// loop until the sum of ticket values is > the winner
while (current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
// ’current’ is the winner: schedule it...
要讓 Lottery Scheduler 達到最高效益的方法是建立一個有排序的 Process List 。
這樣當作業系統要挑選 Process 的效率是最好的。
問題 #
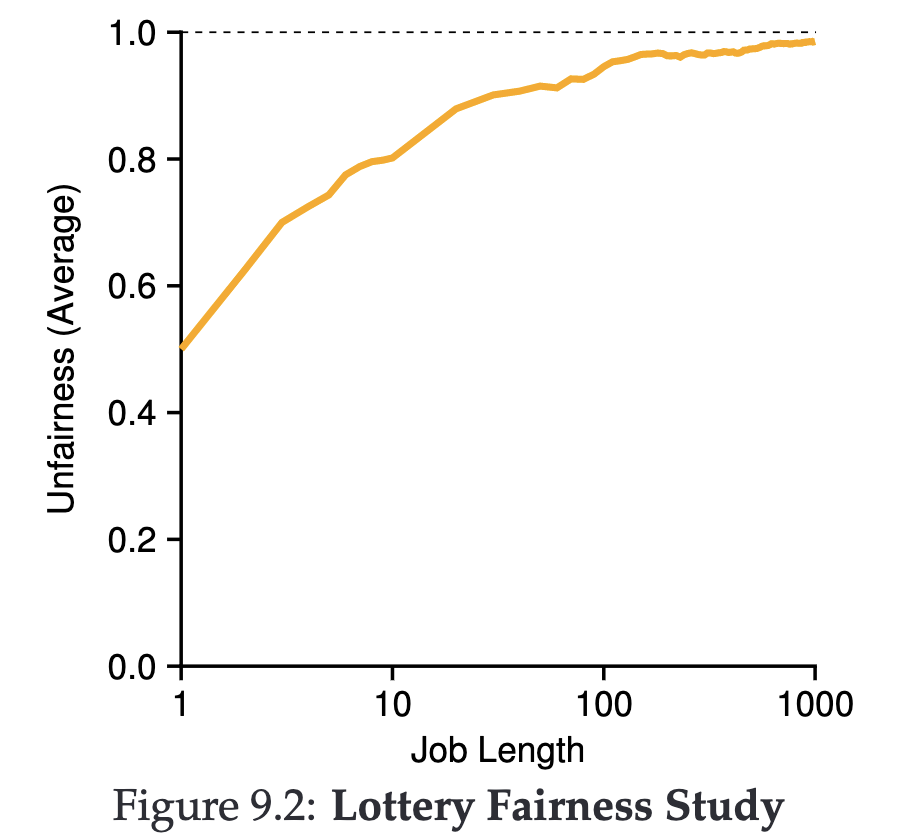
Lottery Scheduling 容易遇到的問題是:Job 執行時間越短,那就有可能出現越不公平的現象。
Stride Scheduling #
為了解決可能出現的不公平現象,我們發展出了另一個 Scheduleing。
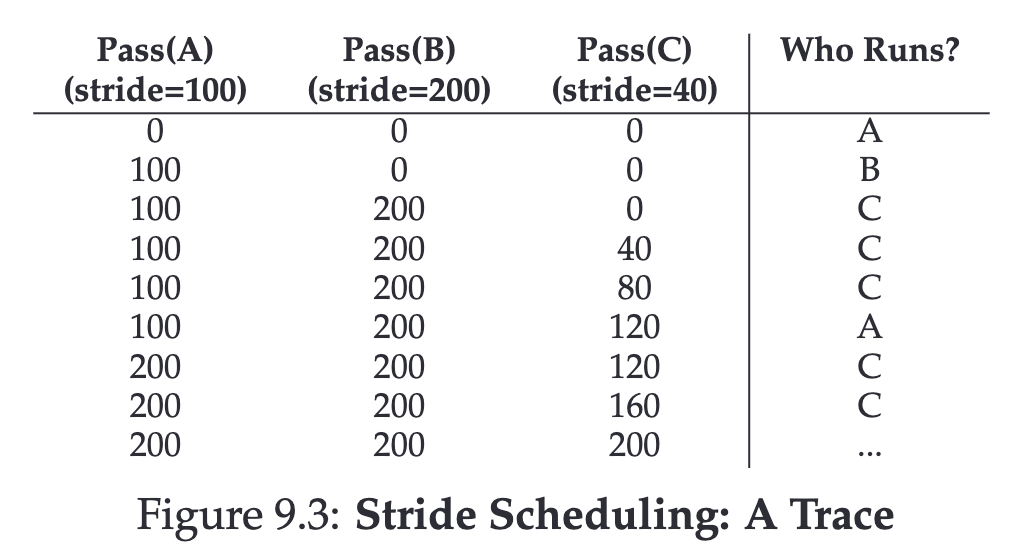
Stride Scheduling 的概念是每個 Job 都有一個步距,這是與它所擁有的票數成反比。
舉例來說
- Process A 有 100 張 ticket
- Process B 有 50 張 ticket
- Process C 有 250 張 ticket
我們可以通過將某個大數字除以每個進程被分配的票數來計算每個的 Stride。例如,如果我們將 10,000 除以這些票數值。我們會得到
- Process A: 100
- Process B: 200
- Process C: 40
每次我們執行該 Process 就加上他們的 Stride 。並且每次都選擇最低 Stride 來執行
範例 #
Completely Fair Scheduler (CFS) #
除了以上將 CPU 等比例分配之外,我們還有另外一種想法。來設計 Scheduler ,我們盡可能的公平分配 CPU 資源給所有的 Process 。
目標 #
盡可能平分 CPU 資源給所有的 Process 。
作法 #
每個 Process 被執行時,都計算被執行的時間長度(vruntime)。
每次切換 Process 的機會,都去選擇 vruntime 最小的 Process 。
在 CFS 裡面有兩個關鍵的參數
sched_latency: 每次執行 Process 的時間長度(通常為 48 ms)min_granularity: 執行 Process 的最短時間(通常為 6ms)
舉個例子,在一個系統內有 4 個 Process 。執行時間就會是 48 / 4 = 12 ms ,每執行 12 ms 就會換執行其他 Process 。
另一個例子,在一個系統內有 10 個 Process 。執行時間就會是 48 / 10 = 4.8 ms ,但因為有 min_granularity 的設定,每執行 6 ms 就會換執行其他 Process 。
範例 #
- 有 4 個 Process 在運行
- CFS 將
sched_latency的值除以 4 ,每個 Process 的 time slice 為 12 ms。 - CFS 接著執行第一個 Process ,並運行它直到它使用了 12 ms (vruntime),然後檢查是否有虛擬運行時間較低的 Process 可運行。
- CFS 將切換到其他三個 Process 之一,依此類推。
- 四個 Process(A, B, C, D)都以這種方式各運行兩個 time slice;其中兩個(C, D)隨後完成,只留下兩個,然後以循環方式各運行 24 ms。
權重 #
CFS 同時也提供優先級的功能(nice),根據不同設定的 nice 有不同的權重。Weight。
然後再根據 Weight 去計算可運行的時間

提升 Scheduler 效率 #
影響 Scheduler 效率的地方有很多,其中一個就是當 Scheduler 決定好要執行哪一個 Process 後,要盡快的找到該 Process 。
在 CFS 中,Processes 使用紅黑樹來管理。